10.1 배열
배열은 다음과 같은 형식으로 선언한다.
// 데이터_타입[] 배열_이름 = new 데이터_타입[용량];
int[] scores = new int[5];배열의 각 요소에 데이터를 저장하거나, 요소 안에 있는 데이터를 읽어올 때는 배열 이름 뒤에 대괄호 [와 ]를 붙여주고, 그 사이에 인덱스(index)를 적어준다. 주의할 점은 인덱스는 1이 아닌 0부터 시작한다는 것이다.

int[] scores = new int[5];
score[0] = 80;
score[1] = 74;
score[2] = 81;
score[3] = 90;
score[4] = 34;
같은 성격의 데이터라면 변수를 사용하는 것보다 배열로 정의한 다음 for문이나 foreach문과 함께 사용하는 것이 코드를 간결하게 만들 수 있다.
배열의 마지막 인덱스는 배열길이-1로 지정한다. 첫 번째 요소를 기준으로 접근할 때는 불편이 없지만, 마지막 요소를 기준으로 접근하고 싶을 때는 트릭이 필요하다.
int[] socres = new int[5];
scores[scores.Length-1] = 34; // scores[4] = 34; 와 동일
C# 8.0부터는 이런 불편을 없애기 없앤 System.Index 타입과 ^연산자가 생겼다. ^ 연산자는 컬렉션의 마지막 역순으로 인덱스를 지정하는 기능을 갖고 있다.
^1은 컬렉션의 마지막 요소를 나타내는 인덱스, ^2는 마지막에서 두 번째, ^3은 마지막에서 세 번째를 나타내는 인덱스다.
어렵다면 ^연산자를 Length와 같다고 생각한다. ^0은 scores.Length-0 이라고 생각한다. 그러면 예외를 일으킬 것이다.
^ 연산자의 결과는 Syste.Index 타입의 인스턴스로 나타난다.
System.Index last = ^1;
scores[last] = 34; // scores[scores.Length-1] = 34;와 동일
다음과 같이 System.Index의 인스턴스를 만들지 않는 더 간결한 버전도 가능하다.
scores[^1] = 34; // scores[scores.Length-1] = 34;와 동일
10.2 배열을 초기화하는 세 가지 방법
첫 번째 방법
배열의 원소 개수를 명시하고, 그 뒤에 중ㅇ괄호 {와 }로 둘러싸인 블록을 붙인 뒤, 블록 사이에 배열의 각 원소에 입력될 데이터를 입력한다. 이렇게 배열 객체를 초기화하는 {} 블록을 일컬어 컬렉션 초기자(Collection Initializer)라고 부른다.
string[] array1 = new string[3] {"안녕", "Hello", "Halo"};
두 번째 방법
첫 번째 방법에서 배열의 용량을 생략하는 것이다.
string array2 = new string[] {"안녕", "Hello", "Halo"};
세 번째 방법
new 연산자, 타입과 대괄호 [와 ], 배열의 용량을 모두 생략한 채 코드 블록 사이에 배열의 각 원소에 할당할 데이터를 넣어주는 방법이다. 문법은 훨씬 간편해졌지만, 그 결과는 첫 번째 / 두 번째 방법과 똑같다.
string[] array3 = {"안녕", "Hello", "Halo"};
세 가지 배열의 초기화 방법을 보면 가장 간편한 세 번째 방법만 사용할 것 같지만, 그렇지 않다.
코드를 다른 사람이 물려받거나 동료들과 공유해야 할 때는 상대방이 읽기 편하도록 첫 번째 방법을 쓰는 것이 좋다.
10.3 System.Array
C#에서는 모든 것이 객체다. 배열도 객체이며, 당연히 기반이 되는 타입이 있다. .NET의 CTS(Common Type System)에서 배열은 System.Array 클래스에 대응된다.
다음 예제는 int 기반의 배열이 System.Array 타입에서 파생됐음을 보여준다.
using System;
namespace PracticeCSharp
{
class Program
{
static void Main(string[] args)
{
int[] array = new int[] { 10, 30, 20, 7, 1 };
Console.WriteLine($"Type of array : {array.GetType()}");
Console.WriteLine($"Base type of array : {array.GetType().BaseType}");
}
}
}
따라서 System.Array의 특성과 메소드를 파악하면 배열의 특성과 메소드를 알게 되는 셈이며, 보너스로 배열을 이용하여 재미있는 일들도 할 수 있다. 예를 들어 배열의 내부 데이터를 원하는 순서대로 정렬한다든가, 특정 데이터를 배열 속에서 찾아내는 작업들이 있다. System.Array 클래스에는 수십 가지 메소드와 프로퍼티가 있지만, 몇 가지만 알아보자.
| 분류 | 이름 | 설명 |
| 정적 메소드 | Sort() | 배열을 정렬한다. |
| BinarySearch<T>() | 이진 탐색을 수행한다. | |
| IndexOf() | 배열에서 찾고자 하는 특정 데이터의 인덱스를 반환한다. | |
| TrueForAll<T>() | 배열의 모든 요소가 지정한 조건에 부합하는지의 여부를 반환한다. | |
| FindIndex<T>() | 배열에서 지정한 조건에 부합하는 첫 번째 요소의 인덱스를 반환한다. IndexOf() 메소드가 특정 값을 갖는 데 비해, FindIndex<T>() 메소드는 지정한 조건에 바탕하여 값을 찾는다. |
|
| Resize<T>() | 배열의 크기를 재조정한다. | |
| Clear() | 배열의 모든 요소를 초기화한다. 배열이 숫자 타입 기반이면 0으로, 논리 타입 기반이면 false로, 참조 타입 기반이면 null로 초기화한다. | |
| ForEach<T>() | 배열의 모든 요소에 대해 동일한 작업을 수행하게 된다. | |
| Copy<T>() | 배열의 일부를 다른 배열에 복사한다. | |
| 인스턴스 메소드 | GetLength() | 배열에서 지정한 차원의 길이를 반환한다. 다차원 배열에서 유용하게 사용된다. |
| 프로퍼티 | Length | 배열의 길이를 반환한다. |
| Rank | 배열의 차원을 반환한다. |
뒤에 <T>를 붙이고 다니는 메소드가 표에 있었다.
<T>는 타입 매개변수(Type Parameter)라고 하는데, 이들 메소드를 호출할 때는 T 대신 배열의 기반 자료형을 인수로 입력하면 컴파일러가 해당 타입에 맞춰 동작하도록 메소드를 컴파일한다.
using System;
namespace PracticeCSharp
{
class Program
{
private static bool CheckPassed(int score)
{
return score >= 60;
}
private static void Print(int value)
{
Console.Write($"{value}");
}
static void Main(string[] args)
{
int[] scores = new int[] { 80, 74, 81, 90, 34 };
foreach(int score in scores)
Console.Write($"{score} ");
Console.WriteLine();
Array.Sort(scores);
Array.ForEach<int>(scores, new Action<int>(Print));
Console.WriteLine();
Console.WriteLine($"Number of dimensions : {scores.Rank}");
Console.WriteLine($"Binary Search : 81 is at " +
$"{Array.BinarySearch<int>(scores, 81)}");
Console.WriteLine($"Linear Search : 90 is at " +
$"{Array.IndexOf(scores, 90)}");
// TrueForAll 메소드는 배열과 함께 조건을 검사하는 메소드를 매개변수로 받는다.
Console.WriteLine($"Everyone passed ? : " +
$"{Array.TrueForAll<int>(scores, CheckPassed)}");
// FindIndex 메소드는 특정 조건에 부합하는 메소드를 매개변수로 받는다.
// 여기선 람다식을 이용해 구현했다.
int index = Array.FindIndex<int>(scores, (score) => score < 60);
scores[index] = 61;
Console.WriteLine($"Everyone passed ? : " +
$"{Array.TrueForAll<int>(scores, CheckPassed)}");
// GetLength(0)은 행의 길이를 구한다.
Console.WriteLine("Old length of scores : " +
$"{scores.GetLength(0)}");
Array.Resize<int>(ref scores, 10); // 5였던 배열의 용량을 10으로 재조정한다.
Console.WriteLine($"New length of scores : {scores.Length}");
Array.ForEach<int>(scores, new Action<int>(Print)); // Action 대리자
Console.WriteLine();
Array.Clear(scores, 3, 7); // 3번 인덱스부터 7글자 초기화
Array.ForEach(scores, new Action<int>(Print));
Console.WriteLine();
int[] sliced = new int[3];
// scores의 0번 인덱스부터 3개 요소를 sliced의 0에서부터 3개 요소에 차례대로 복사
Array.Copy(scores, 0, sliced, 0, 3);
Array.ForEach<int>(sliced, new Action<int>(Print));
Console.WriteLine();
}
}
}
10.4 배열 분할하기
C# 8.0에서 System.Index 타입과 함께 도입된 System.Range가 있다.
System.Range는 시작 인덱스와 마지막 인덱스를 이용해서 범위를 나타낸다.
System.Range 객체를 생성할 때는 '..' 연산자를 이용한다. '..'연산자는 왼쪽에는 시작 인덱스, 오른쪽에는 마지막 인덱스가 온다.
// [와 ] 사이에 인덱스 대신 System.Range 객체를 입력하면 분할된 배열이 반환된다.
System.Range r1 = 0..3;
int[] sliced = scores[r1];
int[] sliced2 = scores[0..3]; // [,와 ] 사이에 직접 .. 연산자를 입력하면 코드가 간결해진다.주의할 점은 '..' 연산자의 두 번째 피연산자, 즉 마지막 인덱스는 배열 분할 결과에서 제외된다.
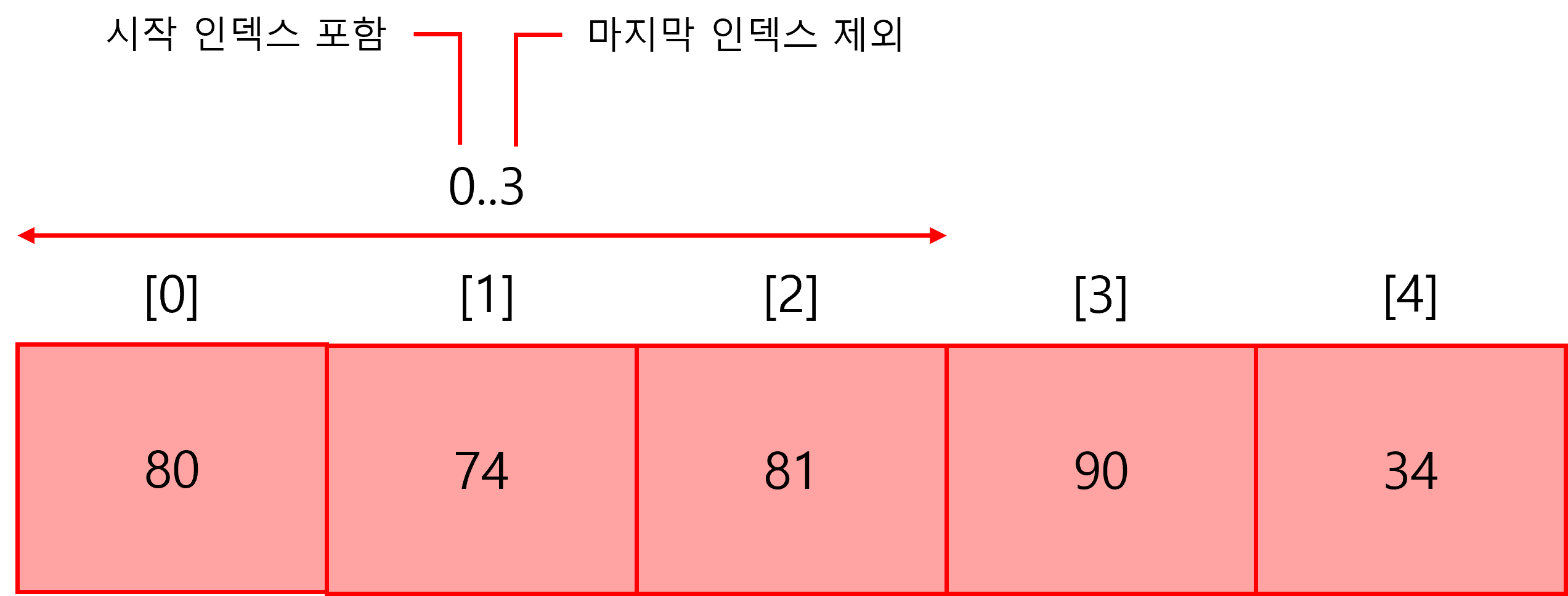
.. 연산자가 받아들이는 두 연산자는 생략할 수 있다. 싲가 인덱스를 생략하려면 ..연산자는 배열의 첫 번째 요소의 위치를 시작 인덱스로 간주한다. 마지막 인덱스를 생략하면 마지막 요소의 위치를 마지막 인덱스로 간주한다.
[..]처럼 시작과 마지막 인덱스를 모두 생략하면 첫 번째 요소의 위치가 시작 인덱스, 마지막 요소의 위치가 마지막 인덱스가 되어 배열 전체를 나타내는 System.Range 객체를 반환한다.
// 첫 번째(0) 요소부터 세 번째(2) 요소까지
int[] sliced3 = scores[..3];
// 두 번째(1) 요소부터 마지막 요소까지
int[] sliced4 = scores[1..];
// 전체
int[] sliced5 = scores[..];
System.Range 객체를 생성할 때 System.Index 객체를 이용할 수 있다.
System.Index idx = ^1;
int[] sliced5 = scores[..idx];
// System.Index 객체를 생성하지 않고 ^연산자를 직접 입력하면 코드가 더 간결해진다.
int[] sliced6 = scores[..^1];
10.5 2차원 배열
2차원 배열은 1차원 배열을 원소로 갖는 배열이라고 할 수 있다.
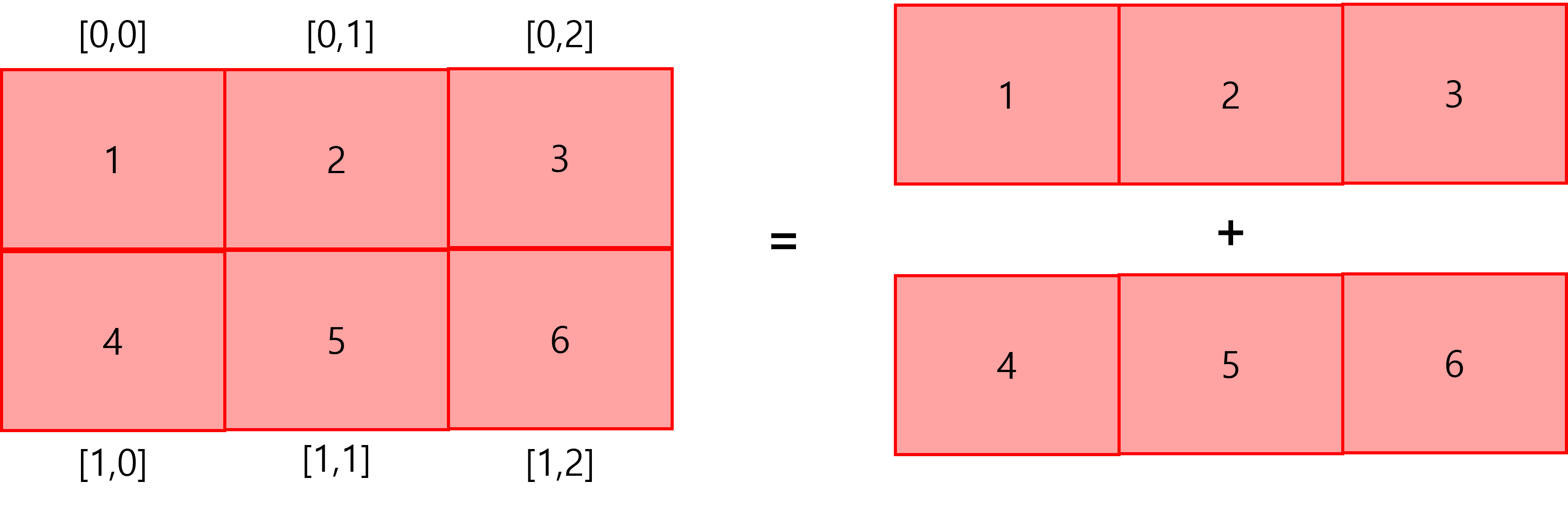
다음 그림은 1차원 (가로 방향)의 길이가 3이고 2차원 (세로 방향)의 길이가 2인 2차원 배열이다.

2차원 배열을 선언하는 방법은 다음과 같다. 기본적으로는 1차원 배열과 선언 형식이 같지만 각 차원의 용량 또는 길이를 콤마(,)로 구분해서 대괄호[와 ] 사이에 입력해준다는 점이 다르다.
데이터_타입[,] 배열이름 = new 데이터_타입[2차원_길이, 1차원_길이];위의 그림과 같은 2 x 3 크기의 int 타입 2차원 배열은 다음과 같이 선언할 수 있다.
int[,] array = new int[2,3];
array[0,0] = 1;
array[0,1] = 2;
array[0,2] = 3;
array[1,0] = 4;
array[1,1] = 5;
array[1,2] = 6;
2차원 배열 코드에서 읽을 때는 [ ] 안에 있는 차원의 길이를 뒤에서부터 읽으면 이해하기 쉽다.
예를 들면 int[2,3]은 기반 타입이 int이며 길이는 3인 1차원 배열을 원소로 2개 갖고 있는 2차원 배열이라고 읽는 식이다.
2차원 배열의 원소에 접근할 때는 첫 번째 차원과 두 번째 차원의 인덱스를 대괄호 [와 ] 사이에 같이 입력해줘야 한다.
다음은 배열의 원소에 접근하는 예제다.
Console.WriteLine(array[0,2]);
Console.WriteLine(array[1,1));
2차원 배열을 선언과 동시에 초기화하고 싶다면, 1차원 배열의 세 가지 초기화 방법을 다음과 같은 형태로 사용할 수 있다.
int[,] arr = new int[2,3]{{1, 2, 3}, {4, 5, 6}}; // 배열의 타입과 길이를 명시
int[,] arr2 = new int[,] {{1, 2, 3}, {4, 5, 6}}; // 배열의 길이를 생략
int[,] arr3 = {{1, 2, 3}, {4, 5, 6}} // 타입과 길이를 모두 생략
10.6 다차원 배열
다차원 배열이란 차원이 둘 이상인 배열을 말한다. 2차원 배열도 다차원 배열에 해당한다. 다차원 배열을 선언하는 문법은 2차원 배열의 문법과 같다. 다만 차원이 늘어날수록 요소에 접근할 때 사용하는 인덱스의 수가 2개, 3개, ... 의 식으로 늘어나는 점이 다를 뿐이다.
3차원 이상의 배열을 사용하지 않는 것을 권장한다. 그림으로 옮기기 쉽지 않고, 머릿속에 배열의 내용을 유지하는 것은 더 어렵다. 그렇다면 버그가 있는 코드를 작성할 것이다.
다음은 3차원 배열을 선언하고 초기화하는 예제이다. 물론 3차원 배열에서도 배열을 초기화하는 3가지 방법을 모두 사용할 수 있지만, 복잡한 구조의 배열을 선언할 때는 만들려는 배열의 각 차원의 크기를 지정해주는 것이 좋다. 그래야 컴파일러가 초기화 코드와 선언문에 있는 배열의 차원 크기를 비교해서 이상이 없는지 검사할 수 있기 때문이다.
int[, ,] array = new int[4, 3, 2]
{
{{1, 2}, {3, 4}, {5, 6}},
{{1, 4}, {2, 5}, {3, 6}},
{{6, 5}, {4, 3}, {2, 1}},
{{6, 3}, {5, 2}, {4, 1}},
}
10.7 가변 배열
가변 배열(Jagged Array)은 다양한 길이의 배열을 갖는 다차원 배열로 이용될 수 있다.
2차원 배열의 요소에 접근할 때 반드시 첨자 두 개를 사용해야 했다. 하나만 사용해서 1차원 배열에 접근한다거나 하는 일은 불가능했다. 가변 배열은 이러한 다차원 배열과 달리 배열을 요소로 사용해 접근할 수 있다.
가변 길이의 번역에 대해
Jagged는 '들쭉날쭉한' 이라는 뜻을 가진 형용사이다. 가변 배열이라고 하면 배열의 길이를 늘였다 줄였다 할 수 있는 배열을 떠올릴 수 있다. 조심하자.
가변 배열은 다음과 같이 선언한다.
데이터_타입[][] 배열_이름 = new 데이터_타입[가변_배열의_용량][];2차원 배열은 [ ]를 하나만 쓰고 그 안에 첨자를 두 개 사용한 반면, 가변 배열은 [ ] 가 두 개이다. 가변 배열의 요소로 입력되는 배열은 그 길이가 모두 같을 필요가 없다. 그래서 Jagged 배열이라고 하는 것이다.
다음은 가변 배열의 선언 예이다. 용량이 3개인 배열 jagged를 선언한 다음, jagged의 각 요소에 크기가 각각 다른 배열들을 할당한다. 0번 요소에는 길이가 5인 배열, 1번 요소에는 길이가 3인 배열, 그리고 2번 요소에는 길이가 2인 배열을 할당한다.
int[][] jagged = new int[3][];
jagged[0] = new int[5] {1, 2, 3, 4, 5};
jagged[1] = new int[] {10, 20, 30};
jagged[2] = new int[] {100, 200};
가변 배열도 선언과 동시에 초기화가 가능하다.
int[][] jagged2 = new int[][]{
new int[] {1000, 2000},
new int[4] {6, 7, 8, 9} };
10.8 컬렉션 맛보기
컬렉션(Collection)이란, 같은 성격을 띤 데이터의 모음을 담는 자료구조(Data Structure)를 말한다.
사실 배열도 .NET이 제공하는 다양한 컬렉션 자료구조의 일부이다.
.NET의 여타 컬렉션들이 무조건 상속해야 하는 ICollection 인터페이스를 상속함으로써 System.Array 클래스가 컬렉션 종류인 것을 알 수 있다.
.NET은 배열 말고도 다양한 컬렉션 클래스들을 여러 개 제공한다. 네 가지만 알아보자.
1. ArrayList
ArrayList는 가장 배열과 닮은 컬렉션이다. 컬렉션의 요소에 접근할 때는 [ ] 연산자를 이용하고, 특정 위치에 있는 요소에 데이터를 임의로 할당할 수도 있다. 한편, 배열과는 달리 컬렉션을 생성할 때 용량을 미리 지정할 필요 없이 필요에 따라 자동으로 그 용량이 늘어나거나 줄어든다. ArrayList의 가장 큰 장점이다.
ArrayList에서 가장 중요한 메소드는 Add(), RemoveAt(), Insert(), 세 개다.
Add() 메소드는 컬렉션의 마지막에 있는 요소 뒤에 새 요소를 추가하고, RemoveAt() 메소드는 특정 인덱스에 있는 요소를 제거한다. Insert() 메소드는 원하는 위치에 새 요소를 삽입한다.
ArrayList list = new ArrayList();
list.Add(10);
list.Add(20);
list.Add(30);
list.RemoveAt(1); // 20 삭제
list.Insert(1, 25); // 25를 1번 인덱스에 삽입. 즉 10과 30 사이에 25를 삽입
using System;
using System.Collections;
namespace PracticeCSharp
{
class Program
{
static void Main(string[] args)
{
ArrayList list = new ArrayList();
for (int i = 0; i < 5; i++)
list.Add(i);
foreach (object obj in list)
Console.Write($"{obj} ");
Console.WriteLine();
list.Insert(2, 2);
foreach (object obj in list)
Console.Write($"{obj} ");
Console.WriteLine();
list.Add("abc");
list.Add("def");
for (int i = 0; i < list.Count; i++)
Console.Write($"{list[i]} ");
Console.WriteLine();
}
}
}
ArrayList가 다양한 타입의 객체를 담을 수 있는 이유
Add(), Insert() 메소드의 선언을 보면 알 수 있다.
public virtual int Add(Object value)
public virtual void Insert(int index, Object value)object 타입의 매개변수를 받고 있다.
참고) object와 Object는 같다. C#에서는 object를 사용한다. .NET에서는 System.Object인데, using System; 덕분에 Object라고 하는 것이다.
모든 타입은 object를 상속하므로 object 타입으로 간주될 수 있다. 그래서 Add() 메소드에 int 타입의 데이터를 넣더라도 정수 타입 그대로 입력되는 것이 아니라 object 타입으로 박싱(Boxing)되어 입력되는 것이다. 반대로 ArrayList의 요소에 접근해서 사용할 때는 원래의 데이터 타입으로 언박싱(Unboxing)이 이루어진다. 박싱과 언박싱은 작지 않은 오버헤드를 요구하는 작업이다. ArrayList가 다루는 데이터가 많으면 많을수록 이러한 성능 저하는 더욱 늘어난다. 이것은 ArrayList 만의 문제가 아니다. Stack, Queue, Hashtable 등의 컬렉션도 갖고 있다. 해결 방법은 일반화 컬렉션(Generic Collection)이다.
2. Queue
Queue는 대기열, 즉 기다리는 (대기) 줄(열)이라는 뜻이다. Queue 자료구조는 데이터나 작업을 차례대로 입력해뒀다가 입력된 순서대로 하나씩 꺼내 처리하기 위해 사용된다. 배열이나 리스트가 원하는 위치에 자유롭게 접근하는 반면에 Queue는 입력은 오직 뒤에서, 출력은 앞에서만 이루어진다.
OS에서 CPU가 처리해야할 작업을 정리할 때, 프린터가 여러 문서를 출력할 때, 인터넷 동영상 스트리밍 서비스에서 콘텐츠를 버퍼링할 때 등등에 쓰인다.
데이터를 입력하는 것은 Enqueue() 메소드를 이용한다.
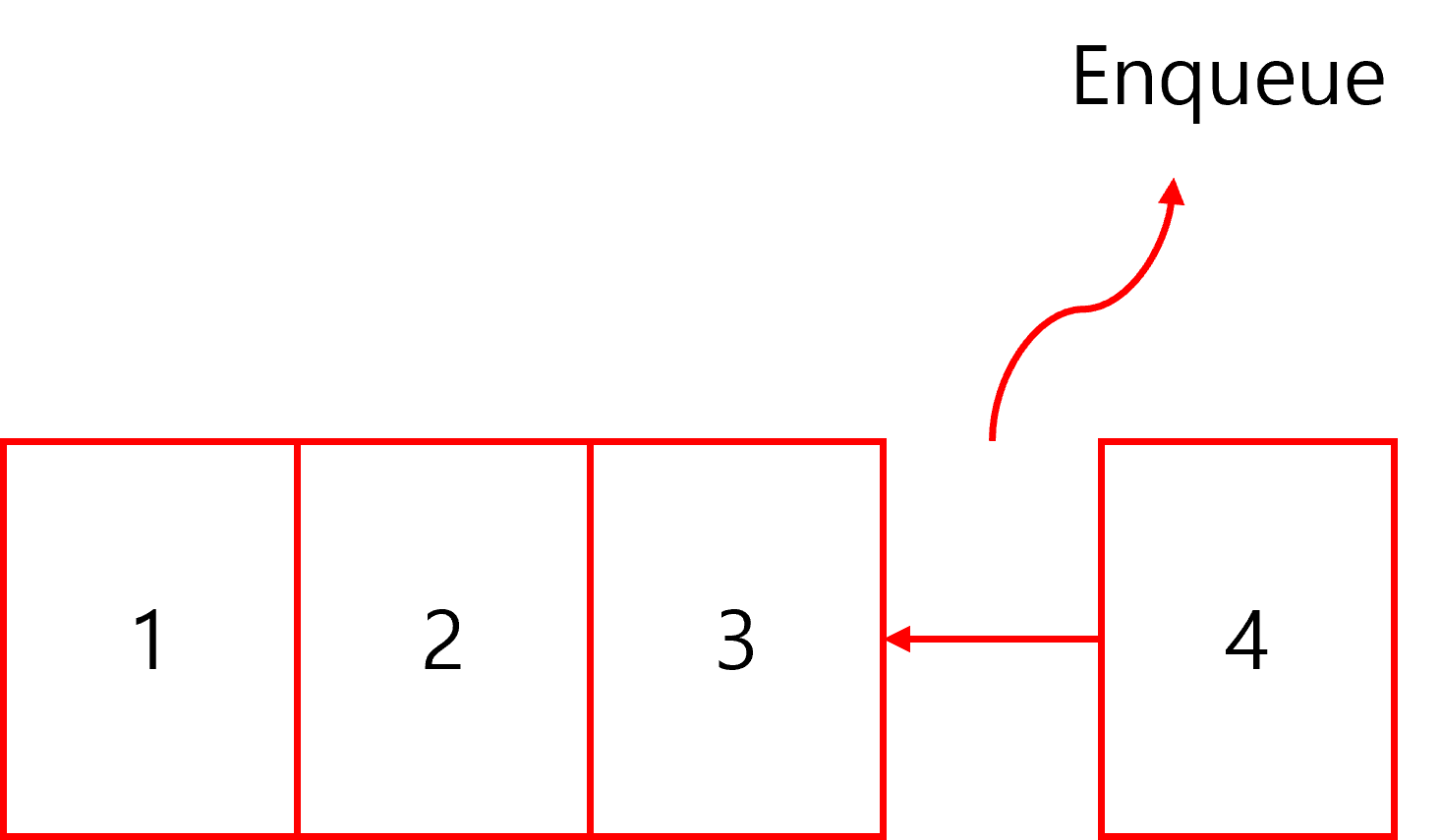
Queue que = new Queue();
que.Enqueue(1);
que.Enqueue(2);
que.Enqueue(3);
que.Enqueue(4);
que.Enqueue(5);
반대로 Queue에서 데이터를 꺼낼 때는 Dequeue() 메소들를 이용한다.
주의할 점은 Dequeue()를 실행하면 데이터를 자료구조에서 실제로 꺼내게 된다.
가장 앞에 있던 항목이 출력되고 나면 그 뒤에 있던 항목이 가장 앞으로 옮겨진다.
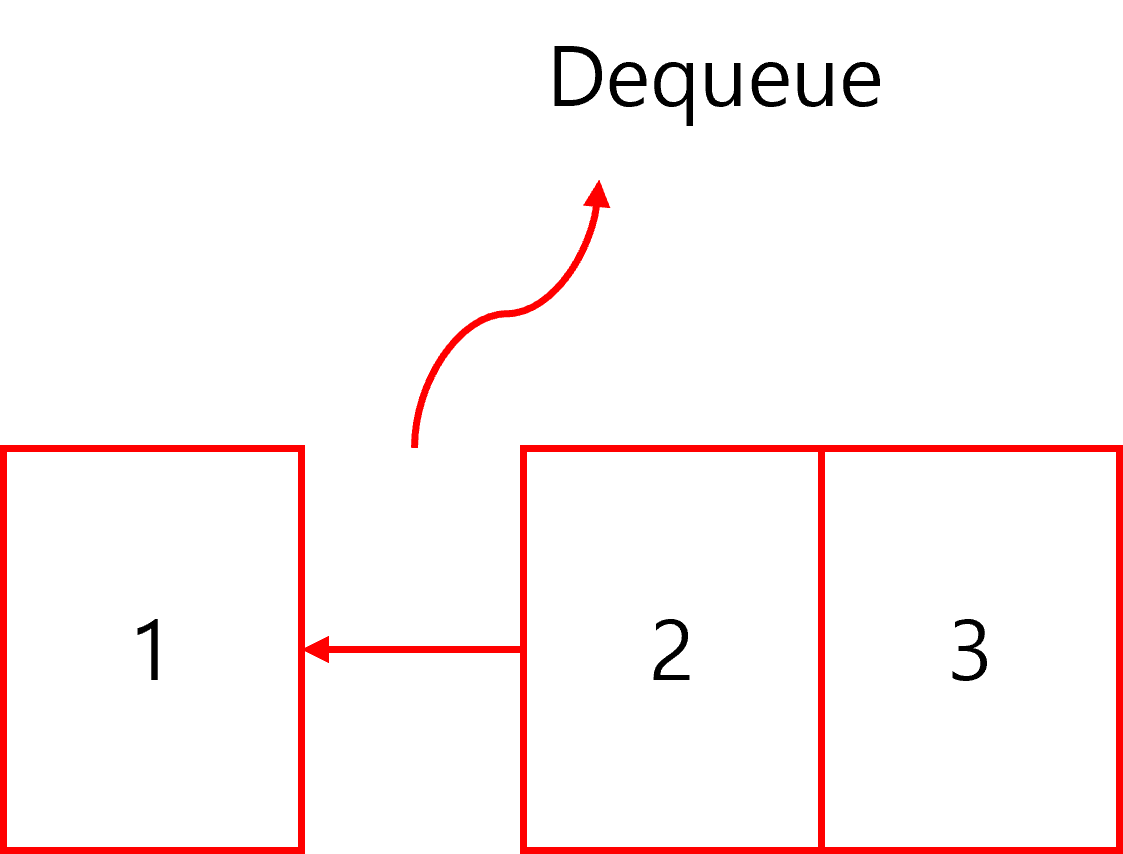
que.Dequeue();
int a = que.Dequeue();
3. Stack
Stack은 먼저 들어온 데이터가 나중에 나가고, 나중에 들어온 데이터가 먼저 나가는 LIFO(Last In - First Out) 구조의 컬렉션이다.
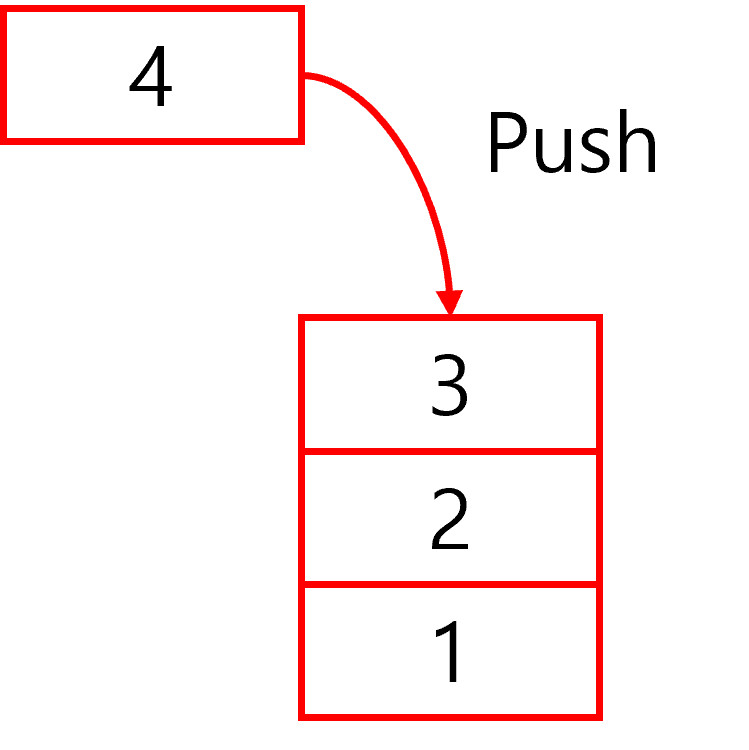

Stack에 데이터를 넣을 때는 Push() 메소드를 이용하고 데이터를 꺼낼 때는 Pop() 메소드를 이용한다.
Push() 메소드는 데이터를 위에 '쌓고', Pop() 메소드는 가장 위에 쌓여 있는 데이터를 '꺼낸다'
Pop()을 호출하여 데이터를 Stack에서 꺼내고 나면 그 데이터는 컬렉션에서 제거되고 그 아래에 있떤 데이터가 가장 위로 올라오게 된다.
Stack stack = new Stack();
stack.Push(1); // 최상위 데이터는 1
stack.Push(2); // 최상위 데이터는 2
stack.Push(3); // 최상위 데이터는 3
int a = (int)stack.Pop(); // 최상위 데이터는 다시 2
4. Hashtable
Hashtable은 키(Key)와 값(Value)의 쌍으로 이루어진 데이터를 다룰 때 사용한다. 예로는 사전이 있다.
Hashtable은 여러 면에서 멋진 자료구조다. 왜냐하면 탐색 속도가 빠르고 사용하기도 편하기 때문이다.
Hashtable ht = new Hashtable();
ht["book"] = "책";
ht["cook"] = "요리사";
ht["tweet"] = "지저귀다"
Console.WriteLine(ht["book"]);
Console.WriteLine(ht["cook"]);
Console.WriteLine(ht["tweet"]);
Hashtable 컬렉션은 키 데이터를 그대로 사용한다.
Hashtable은 배열에서 인덱스를 이용해 배열 요소에 접근하는 것에 준하는 탐색속도를 자랑한다.
탐색 속도가 거의 소요되지 않는다. 키를 이용해서 단번에 데이터가 저장된 컬랙션 내의 주소를 계산한다.
이 작업을 해싱(Hashing)이라고 한다.
10.9 컬렉션을 초기화하는 방법
컬렉션의 생성자를 호출할 때 배열 객체를 매개변수로 넘기면 컬렉션 객체는 해당 배열을 바탕으로 내부 데이터를 채운다.
int[] arr = {123, 456, 789};
ArrayList list = new ArrayList(arr); // 123, 456, 789
Stack stack = new Stack(arr); // 789, 456, 123
Queue queue = new Queue(arr); // 123, 456, 789
ArrayList는 배열의 도움 없이 직접 컬렉션 초기자를 이용해서 초기화할 수 있다.
// 컬렉션 초기자는 생성자를 호출할 때, 생성자 뒤에 {와 } 사이에 컬렉션 요소의 목록을 입력해 사용한다.
ArrayList list2 = new ArrayList() {11, 22, 33}
Stack과 Queue는 컬렉션 초기자를 이용할 수 없다. 컬렉션 초기자는 IEnumerable 인터페이스와 Add() 메소드를 구현하는 컬렉션만 지원하는데, 이 두 컬렉션은 IEnumberable은 상속하지만 Add() 메소드는 구현하지 않기 때문이다.
Hashtable을 초기화할 때는 딕셔너리 초기자(Dictionary Initializer)를 이용한다. 딕셔너리 초기자는 컬렉션 초기자오 ㅏ비슷하게 생겼다. 다음은 딕셔너리 초기자의 예이다.
Hashtable ht = new Hashtable()
{
["하나"] = 1, // ;가 아니라 ,를 이용하여 항목을 구분한다.
["둘"] = 2,
["셋"] = 3
};
다음 예처럼 Hashtable을 초기화할 때도 컬렉션 초기자를 사용할 수 있다. 하지만 쓰기도 편하고 읽기도 수월한 딕셔너리 초기자를 권한다.
Hashtable ht2 = new Hashtable()
{
{"하나", 1},
{"둘", 2},
{"셋", 3}
}
10.10 인덱서
인덱서(Indexer)는 인덱스를 이용해서 객체 내의 데이터에 접근하게 해주는 프로퍼티라고 생각하면 이해하기 쉽다.
객체를 마치 배열처럼 사용할 수 있게 해준다. 인덱서를 선언하는 형식은 다음과 같다.
class 클래스_이름
{
한정자 인덱서_타입 this[타입 index]
{
get
{
// index를 이용하여 내부 데이터 반환
}
set
{
// index를 이용하여 내부 데이터 저장
}
}
}인덱서는 프로퍼티처럼 식별자를 따로 가지지 않는다.
프로퍼티가 이름을 통해 객체 내의 데이터에 접근하게 해준다면, 인덱서는 인덱스를 통해 객체 내 데이터에 접근하게 해준다.
class MyList
{
private int[] array;
public MyList()
{
array = new int[3];
}
public int this[int index] // 인덱서
{
get
{
return array[index];
}
set
{
if(index >= array.Length)
{
Array.Resize<int>(ref array, index + 1);
Console.WriteLine("Array Resized : {0}", array.Length);
}
array[index] = value
}
}
}
프로퍼티는 객체 내의 데이터에 접근할 수 있도록 하는 통로이다. 인덱서도 프로퍼티처럼 객체 내의 데이터에 접근할 수 있도록 하는 통로이다. 프로퍼티와 다른 점이라면 '인덱스'를 이용한다는 것이다.
using System;
using System.Collections;
namespace PracticeCSharp
{
class MyList
{
private int[] array;
public MyList()
{
array = new int[3];
}
public int this[int index]
{
get
{
return array[index];
}
set
{
if(index >= array.Length)
{
Array.Resize<int>(ref array, index + 1);
Console.WriteLine($"Array Resized : {array.Length}");
}
array[index] = value;
}
}
public int Length
{
get { return array.Length; }
}
}
class Program
{
static void Main(string[] args)
{
MyList list = new MyList();
for (int i = 0; i < 5; i++)
list[i] = i; // 배열을 다루듯 인덱스를 통해 데이터를 입력한다.
for(int i=0; i<list.Length; i++)
Console.WriteLine(list[i]); // 데이터를 얻어올 때도 인덱스를 이용한다.
}
}
}
10.11 foreach가 가능한 객체 만들기
foreach문은 for문처럼 요소의 위치를 위한 인덱스 변수를 선언할 필요가 없다. 세미콜론을 2개나 넣지 않아도 되고, 조건문이나 증감식을 쓰지 않아도 된다. for문을 이용한 코드에 비해 foreach문을 이용한 코드는 쓰기도 좋고, 읽기도 좋다.
foreach문은 아무 타입의 객체에서나 사용할 수 있는 것이 아니다. 배열이나 리스트 같은 컬렉션에서만 사용할 수 있다.
foreach문이 객체 내 요소를 순회하기 위해서는 IEnumerable을 상속하는 타입이여야 한다.
IEnumerable 인터페이스가 갖고 있는 메소드는 다음과 같이 단 하나뿐이다.
| 메소드 | 설명 |
| IEnumerator GetEnumerator() | IEnumerator 타입의 객체를 반환 |
GetEnumerator()는 IEnumerator 인터페이스를 상속하는 클래스의 객체를 반환해야 한다.
yield문을 이용하면 IEnumerator를 상속하는 클래스를 따로 구현하지 않아도 컴파일러가 자동으로 해당 인터페이스를 구현한 클래스를 생성해준다. yield return 문은 현재 메소드(GetEnumerator())의 실행을 일시 정지핸호고 호출자에게 결과를 반환한다. 메소드가 다시 호출되면, 일시 정지된 실행을 복구하여 yield return 또는 yield break문을 만날 때까지 나머지 작업을 실행하게 된다.
using System;
using System.Collections;
namespace PracticeCSharp
{
class MyEnumerator
{
int[] numbers = { 1, 2, 3, 4 };
public IEnumerator GetEnumerator()
{
yield return numbers[0];
yield return numbers[1];
yield return numbers[2];
// yield break는 GetEnumerator() 메소드를 종료시킨다.
yield break;
yield return numbers[3]; // 실행 안됨
}
}
class Program
{
static void Main(string[] args)
{
var obj = new MyEnumerator();
foreach (int i in obj)
Console.WriteLine(i);
}
}
}
GetEnumerator() 메소드는 IEnumerator 타입의 객체, 다시 말해 IEnumerator 인터페이스를 상속하는 클래스의 객체를 반환하면 된다. IEnumerator 인터페이스는 무엇일까?
다음은 IEnumerator 인터페이스의 메소드 및 프로퍼티 목록이다.
| 메소드 또는 프로퍼티 | 설명 |
| boolean MoveNext() | 다음 요소로 이동한다. 컬렉션의 끝을 지난 경우에는 false, 이동이 성공한 경우에는 true를 반환한다. |
| void Reset() | 컬렉션의 첫 번째 위치의 '앞'으로 이동한다. 첫 번째 위치가 0번인 경우 Reset()을 호출하면 -1번으로 이동하는 것이다. 첫 번째 위치로의 이동은 MoveNext()를 호출한 다음에 이루어진다. |
| Object Current {get;} | 컬렉션의 현재 요소를 반환한다. |
앞에서 yield문의 도움을 받아 IEnumerator를 상속하는 클래스 구현을 피했는데, 이번에는 직접 IEnumerator를 상속하는 클래스를 구현해보자.
using System;
using System.Collections;
namespace PracticeCSharp
{
class MyList : IEnumerable, IEnumerator
{
private int[] array;
// 컬렉션의 현재 위치를 다루는 변수다. 초깃값은 0이 아닌 -1이다.
// 0은 배열의 첫 번째 요소를 가리키는 수이다.
// position이 이 값(0)을 갖고 있을 때 foreach문이 첫 번째 반복을 수행하면
// MoveNext() 메소들르 실행하고, 이 때 position이 1이 되어 두 번재 요소를 가져오는 문제가 생긴다.
int position = -1;
public MyList()
{
array = new int[3];
}
public int this[int index]
{
get
{
return array[index];
}
set
{
if(index >= array.Length)
{
Array.Resize<int>(ref array, index + 1);
Console.WriteLine($"Array Resized : {array.Length}");
}
array[index] = value;
}
}
// IEnumerator 멤버
public object Current // IEnumerator로부터 상속받은 Current 프로퍼티는 현재 위치의 요소를 반환한다.
{
get
{
return array[position];
}
}
// IEnumerator 멤버
public bool MoveNext() // IEnumerator 로부터 상속받은 MoveNext() 메소드. 다음 위치의 요소로 이동한다.
{
if(position == array.Length - 1)
{
Reset();
return false;
}
position++;
return (position < array.Length);
}
// IEnumerator 멤버
public void Reset() // IEnumerator 로부터 상속받은 Reset() 메소드. 요소의 위치를 첫 요소의 '앞'으로 옮긴다.
{
position = -1;
}
// IEnumerable 멤버
public IEnumerator GetEnumerator()
{
return this;
}
}
class Program
{
static void Main(string[] args)
{
MyList list = new MyList();
for (int i = 0; i < 5; i++)
list[i] = i;
foreach(int e in list)
Console.WriteLine(e);
}
}
}
'공부 > C#' 카테고리의 다른 글
| 이것이 C#이다 Chapter 12 예외 처리하기 (0) | 2024.03.09 |
|---|---|
| 이것이 C#이다 Chapter 11 일반화 프로그래밍 (0) | 2024.03.09 |
| 이것이 C#이다 Chapter 09 프로퍼티 (2) | 2024.03.07 |
| 이것이 C#이다 Chapter 08 인터페이스와 추상 클래스 (0) | 2024.03.06 |
| 이것이 C#이다 Chapter 07 클래스 (1) | 2024.02.27 |